How to find the latest folder and unzip it using Python in the DataBricks notebook (On Top of AWS )?

Introduction
In this blog, we are going to talk about how to find the latest folder and how to unzip it using Python in the databricks notebook.
Pre-requisites to try out this blog
- AWS Account (without this, we can fetch the files from the S3 bucket, but we can’t use the DataBricks cluster as well, (which is really important).
- Databricks Community Account (it has a 14-day free trial and will not ask you for credit card details!! :P )
- Python Knowledge (Ah ! necessary)
- Proper Permissions to use databricks with your AWS account (check the bottom of this blog for setup links that you can follow all along)
What is Databricks ?
Databricks is a single, cloud-based platform that can handle all of your data needs, which means it’s also a single platform on which your entire data team can collaborate. Databricks is fast, cost-effective, and inherently scales to very large data sets. Databricks is run on top of your existing cloud, whether that’s Amazon Web Services (AWS), Microsoft Azure, Google Cloud, or even a multi-cloud combination of those.
What is Mount Point and How to create mount point in Databricks?
A Mount Point is a directory in a file system where additional information is logically connected from storage locations outside the operating system’s root device and partitions. For Example,
S3 Bucket, USB drives, etc. (which are external storage devices and locations). To help us access the group of files in a file system structure for a user or a user group.
Databricks has its own utility library called dbutils. It helps us perform powerful combinations of tasks.
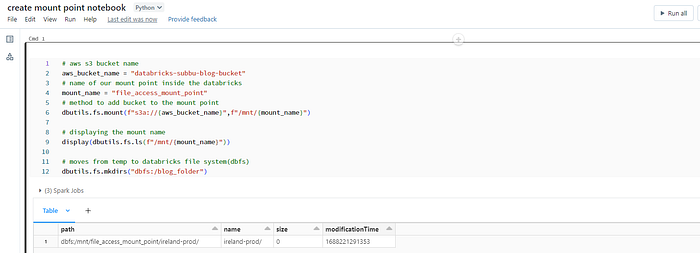
In the below code block using Python, we will be using dbutils.fs.mount() to create a mount in the databricks by passing two parameters in the function: the first is the external storage you want to connect, like in our case, AWS S3 Bucket, and another parameter will be the name of our mount point. In our case, we are going to name it as file_access_mount_point. Even You can add extra configurations inside dbutils.fs.mount() by mentioning extra_configs=//something as a third parameter.
# aws s3 bucket name
aws_bucket_name = "databricks-subbu-blog-bucket"
# name of our mount point inside the databricks
mount_name = "file_access_mount_point"
# method to add bucket to the mount point
dbutils.fs.mount(f"s3a://{aws_bucket_name}",f"/mnt/{mount_name}")
# displaying the mount name
display(dbutils.fs.ls(f"/mnt/{mount_name}"))
# moves from temp to databricks file system(dbfs)
dbutils.fs.mkdirs("dbfs:/blog_folder")How to find the latest folder from the mount location ?
To find the latest folder from the mount location. We are going to create a function that takes the directory as an input and processes it. Inside the function, we are going to use the Python library called glob, which helps us find all the pathnames that match a specified pattern according to the rules used by the Unix shell, and the results are returned in an arbitrary order.
import glob
import os
import datetime
import time
def get_latest_folder(dir_path):
directory_list_dict = {}
directories = glob.glob(f"{dir_path}/*")
date_list = []
for d in directories:
latest_file_key = max(glob.glob(f"{d}/*"), key=os.path.getctime)
file_arr_time = time.strftime(
"%m/%d/%Y", time.gmtime(os.path.getmtime(latest_file_key))
)
date_val = datetime.datetime.strptime(file_arr_time, "%m/%d/%Y")
directory_list_dict[date_val] = latest_file_key
date_list.append(date_val)
max_date = max(date_list)
latest_file = directory_list_dict[max_date]
latest_directory = latest_file.rsplit("/", 1)[0]
return latest_directoryIn the above-mentioned code block, we are using glob.glob() to get the directories in the form of a list of pathnames, as it matches the pattern dir_path/*. We are iterating over the directories list, which we get from the pattern we pass to the glob.glob() method. While iterating over the directories list, we are getting the latest_file_key max of the system’s ctime for the specified path. We are storing the file_arr_time in the format of %m/%d/%Y by the latest modification time of the specified path using time.strftime() and by using datetime.datetime.strptime() with file_arr_time to get the date value in a format, store the latest_file_key as a value of the date_val key in the directory_list_dict dictionary, and append the date_val to the date_list.
After these processes, we are getting the latest_file from the directory_list_dict and will right-split the value and return it as latest_directory.
The next step is to store the value from get_latest_folder() in the local environment variable for further use. Using os.environ() to use in the shell command along with a wildcard pattern.
latest_folder = get_latest_folder('/dbfs/mnt/file_access_mount_point')
os.environ['LATEST'] = latest_folder
print(os.getenv('LATEST'))After loading this latest_folder into the environment variable, we can use this variable inside the shell command. Now we are going to copy the latest folders into the folder we created in dbfs (Databricks File Systems) by running the shell command cp $LATEST/* /dbfs/blog_folder/. And creating an extract folder inside /dbfs/blog_folder/ to move the extracted files into it.
Unzipping the files from latest folder
Finally, we come to the most important part of this blog! UNZIPPING !!!
Once we are done with all of the steps, we can now proceed with one more step to unzip the files from the latest folder whose response we copied to the /dbfs/blog_folder/ path into the /dbfs/blog_folder/extract folder.
By executing this code block, we will be using os.system() to execute the command.
dirs = os.listdir('/dbfs/blog_folder/')
for file in dirs:
if file.endswith('.zip'):
unzip_cmd = f"unzip /dbfs/blog_folder/{file} -d /dbfs/blog_folder/extract"
print(f"The unzip command {unzip_cmd}")
os.system(unzip_cmd)We have seen the numbers of the code blocks that we need for “Unzipping the files from the latest folder”. Now we need to copy those code blocks and put them inside the “DATABRICKS Notebooks”.
The Order of the notebook will be:
- Creation of Mount Point
- Unzipping the files from the latest folder
Both of these notebooks are in Python.
1. Creation of Mount Point Notebook
2. Unzipping the files from latest folder Notebook Output

Conclusion:
Yup ! We have come to the most exciting part of the blog! Conclusion!!!!!!!
By the above-mentioned way, we can get the latest folder and its files from the S3 bucket via mount point in the DATABRICKS Environment. I hope this blog was useful to you. If you find the blog useful, please share it with your peers !!
You can find the code here : https://github.com/subbusainath/databricks-aws-latest-folder
Certain setup for the links of databricks for your information;
https://docs.databricks.com/getting-started/admin-get-started.html
